轻量级文本转语音(TTS)模型是一种可以将书面文本转换为自然听起来的语音输出的计算机软件。这种模型通常设计得更为紧凑,以减少计算资源的需求,使其能够在资源受限的设备上运行,例如在移动设备、嵌入式系统或低功耗设备上。
为了实现高效性,轻量级 TTS 模型采用了以下几种策略:
-
模型架构简化:使用更少的神经网络层或更小的网络结构,减少参数数量。
-
参数量化:将模型的权重从浮点数转换为整数或低精度浮点数,减少模型大小并加速计算。
-
知识蒸馏:从一个大型、复杂的模型(教师模型)中提取知识,转移到一个小型的模型(学生模型)上。
-
频谱合成技术:使用更高效的频谱合成技术,如频域方法,而不是直接在时域上合成波形。
-
模型剪枝:移除神经网络中不重要的连接,进一步减少模型大小。
轻量级 TTS 模型在保持较好的语音自然度的同时,能够在保持较低延迟的情况下快速响应,适用于需要实时语音合成的场合,如语音助手、电子阅读器、车载导航系统等。随着技术的发展,这些模型在保持轻量化的同时,其语音质量和自然度也在不断提高。

HuggingFace 也提供了mini版本Demo项目可以进行体验
(有条件的开发者也可以自行搭建,而且 Parler-TTS 只需一行代码即可安装。)
在线demo:https://huggingface.co/spaces/parler-tts/parler_tts_mini
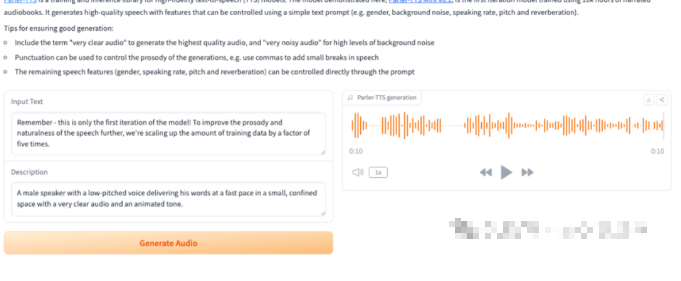
我们进入了Demo界面,回发现他只有 2个输入项,1个输出。
- •
Input Text:需要转语音的文本 - •
Description:对于音频角色、场景、语调、音色等信息的描述,类似于Prompt。比如:一个声音低沉的男性演讲者,在一个狭小的空间里以快速的节奏说话,声音清晰,语调生动。 - •
Parler-TTS generation:生成的音频文件(可试听、下载)
当然,如果想定制声音,也可以根据自己的数据集对该模型进行训练和微调。
© 版权声明
文章版权归作者所有,未经允许请勿转载。