废话不多说,开始我们的极简傻瓜教程。
Ollama 在本地简单的运行llama
Ollama 是一个简化的工具,用于在本地运行开源 LLM,包括 Mistral 和 Llama 2。Ollama 将模型权重、配置和数据集捆绑到一个由 Modelfile 管理的统一包中。Ollama 支持各种 LLM,支持的模型如下:
| Model | Parameters | Size |
|---|---|---|
| Llama 3 | 8B | 4.7GB |
| Llama 3 | 70B | 40GB |
| Mistral | 7B | 4.1GB |
| Dolphin Phi | 2.7B | 1.6GB |
| Phi-2 | 2.7B | 1.7GB |
| Neural Chat | 7B | 4.1GB |
| Starling | 7B | 4.1GB |
| Code Llama | 7B | 3.8GB |
| Llama 2 Uncensored | 7B | 3.8GB |
| Llama 2 13B | 13B | 7.3GB |
| Llama 2 70B | 70B | 39GB |
| Orca Mini | 3B | 1.9GB |
| LLaVA | 7B | 4.5GB |
| Gemma | 2B | 1.4GB |
| Gemma | 7B | 4.8GB |
| Solar | 10.7B | 6.1GB |
地址:https://ollama.com/
安装
网址:https://ollama.com/download
-
从官方网站下载 Ollama。 -
下载后,安装过程简单明了,与其他软件安装类似。对于 MacOS 和 Linux 用户,您可以使用一个命令安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh
windows 也支持预览版了,但是本博主在安装过程中失败,然后放弃采用了windows wsl 在ubuntu上运行,这个在后文介绍。
运行llama3
输入命令
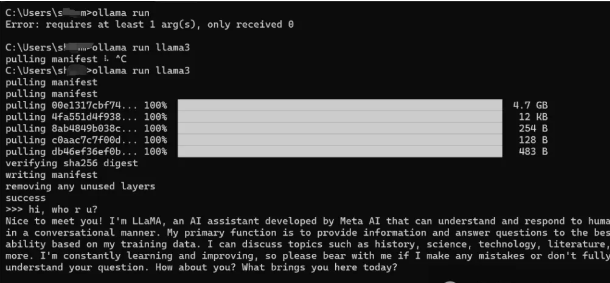
ollama run llama3
界面显示如下,程序会把权重文件下载下来,默认下载的是llama3:8b。
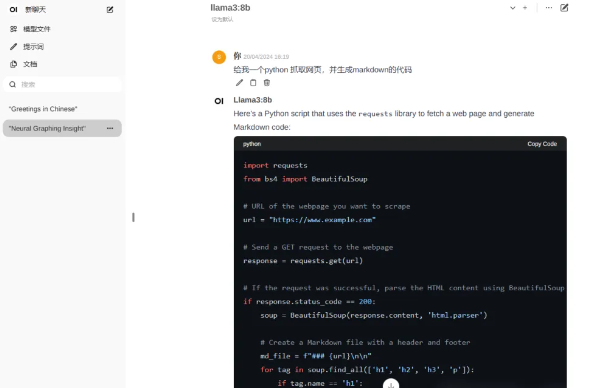
加个web ui来运行,更直观!
这里我采用了开源项目 open-webui,网址:https://github.com/open-webui/open-webui 。该项目的ui和chatgpt非常类似,截图如下:
我打算直接采用该项目的docker镜像来运行,简单快捷,假设你的电脑已经安装了docker.
下载open-webui docker镜像
docker pull ghcr.io/ollama-webui/ollama-webui:main
启动镜像
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
如果你遇到了连接问题,通常是因为 WebUI docker 容器无法访问容器内的 127.0.0.1:11434 (host.docker.internal:11434) 的 Ollama 服务器,使用 docker 命令中的 –network=host 标志来解决这个问题,注意端口从 3000 改为 8080,导致链接:http://localhost:8080 。
访问
输入地址 http://localhost:8080 进行访问,初次访问需要注册。
配置
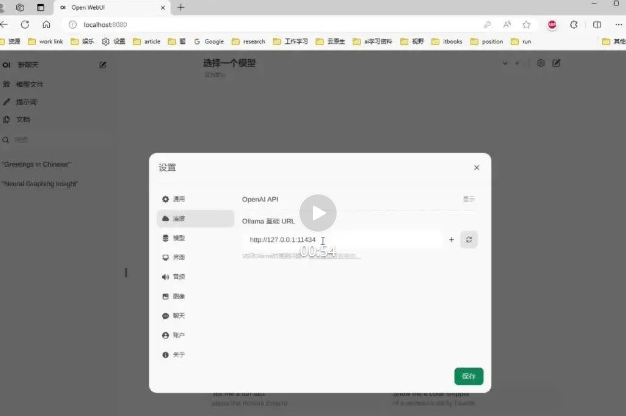
你需要配置Ollama 访问url(配置成http://127.0.0.1:11434) 和 选择模型,录屏如下:
测试效果
将 Ollama 与 Python 结合使用
您也可以将 Ollama 与 Python 一起使用。LiteLLM 是一个 Python 库,它提供了一个统一的接口来与各种 LLM 进行交互,包括 Ollama 运行的 LLM。要将 Ollama 与 LiteLLM 一起使用,您首先需要确保您的 Ollama 服务器正在运行。然后,您可以使用该函数向服务器发出请求。下面是如何执行此操作的示例:litellm.completion
from litellm import completion
response = completion(
model="ollama/llama3",
messages=[{ "content": "respond in 20 words. who are you?", "role": "user"}],
api_base="http://localhost:11434"
)
print(response)
和LlamaIndex、LangChain整合使用
LangChain
from langchain_community.llms import Ollama
llm = Ollama(model="llama3")
llm.invoke("Why is the sky blue?")
Llamaindex
from llama_index.llms.ollama import Ollama
llm = Ollama(model="llama3")
llm.complete("Why is the sky blue?")
补充资料
什么是WSL
不知道各位小伙伴是否有听说过wsl呢?wsl的全程是Windows Subsystem for Linux,也就是windows的linux子系统,也就是我们用再安装虚拟机或者双系统,可以在windows上顺畅的运行linux。
安装指南如下:https://learn.microsoft.com/zh-cn/windows/wsl/install
在WSL中安装cuda来加速模型
前提是你的显卡是英伟达的,可以安装用来加速模型的推理,否则就要靠cpu,回答的速度会降低很多!
安装指南参考:https://github.com/ashishpatel26/Cuda-installation-on-WSL2-Ubuntu-20.04-and-Windows11