项目简介
作为第一个尝试将流匹配和 DiT 相结合的开源 TTS 模型,StableTTS 是一款用于中英文语音生成的快速轻量级 TTS 模型。它只有 10M 参数。
目前工作正在进行中。预训练模型和详细说明即将发布!
推理
有关详细的推理说明,请参阅 inference.ipynb
训练
使用 StableTTS 设置和训练模型非常简单。请按照以下步骤开始操作:
准备数据
-
生成文本和音频对:将文本和音频对文件列表生成为
./filelists/example.txt。开源数据集的一些配方可以在 中找到./recipes。(由于我们使用参考编码器来捕获说话人身份,因此在多说话人合成和训练中不需要说话人 ID。 -
运行预处理:调整
DataConfig输入preprocess.py以设置输入和输出路径,然后运行脚本。这将根据您的列表处理音频和文本,输出一个 JSON 文件,其中包含重新采样音频、mel 特征和音素的路径。注意:确保切换chinese=FalseDataConfig到英语文本处理。
开始训练
-
调整训练配置:在
config.py中,修改TrainConfig以设置文件列表路径并根据需要调整训练参数。 -
启动训练过程:启动
train.py以开始训练模型。
试验配置
随意探索和修改设置 config.py 以修改超参数!
模型结构
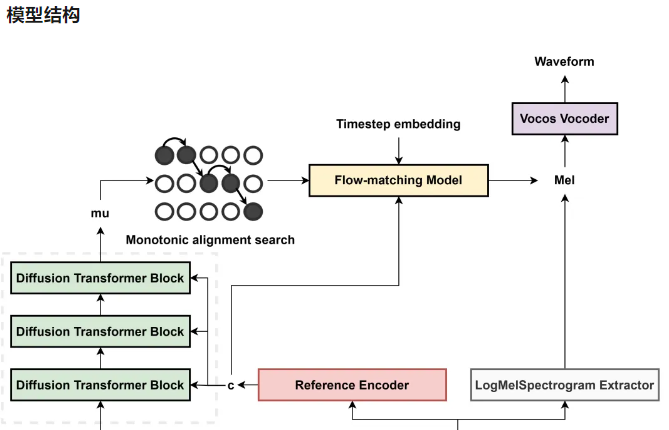
-
我们使用 Hierspeech++ 的扩散卷积转换器模块,它是原始 DiT 和 FFT(来自 fastspeech 的前馈转换器)的组合,以获得更好的韵律。
-
在流匹配解码器中,我们在 DiT 模块之前添加一个 FiLM 层,以条件时间步长嵌入到模型中。
项目链接
http://github.com/KdaiP/StableTTS
© 版权声明
文章版权归作者所有,未经允许请勿转载。